The diffusion model has shown exceptional capabilities in controlled image generation, which has further fueled interest in image style transfer. Existing works mainly focus on training free-based methods (e.g., image inversion) due to the scarcity of specific data. In this study, we present a data construction pipeline for content-style-stylized image triplets that generates and automatically cleanses stylized data triplets. Based on this pipeline, we construct a dataset IMAGStyle, the first large-scale style transfer dataset containing 210k image triplets, available for the community to explore and research. Equipped with IMAGStyle, we propose CSGO, a style transfer model based on end-to-end training, which explicitly decouples content and style features employing independent feature injection. The unified CSGO implements image-driven style transfer, text-driven stylized synthesis, and text editing-driven stylized synthesis. Extensive experiments demonstrate the effectiveness of our approach in enhancing style control capabilities in image generation.
Given any content image C and style image S, CSGO aims to generate a plausible target image by combining the content of one image with the style of another, ensuring that the target image maintains the original content's semantics while adopting the desired style.The following figure outlines our approach. It consists of two key components: (1) content control for extracting content information, which is injected into the base model via Controlnet and decoupled cross-attention module; and (2) style control for extracting style information, which is injected into Controlnet and the base model using the decoupled cross-attention module, respectively.
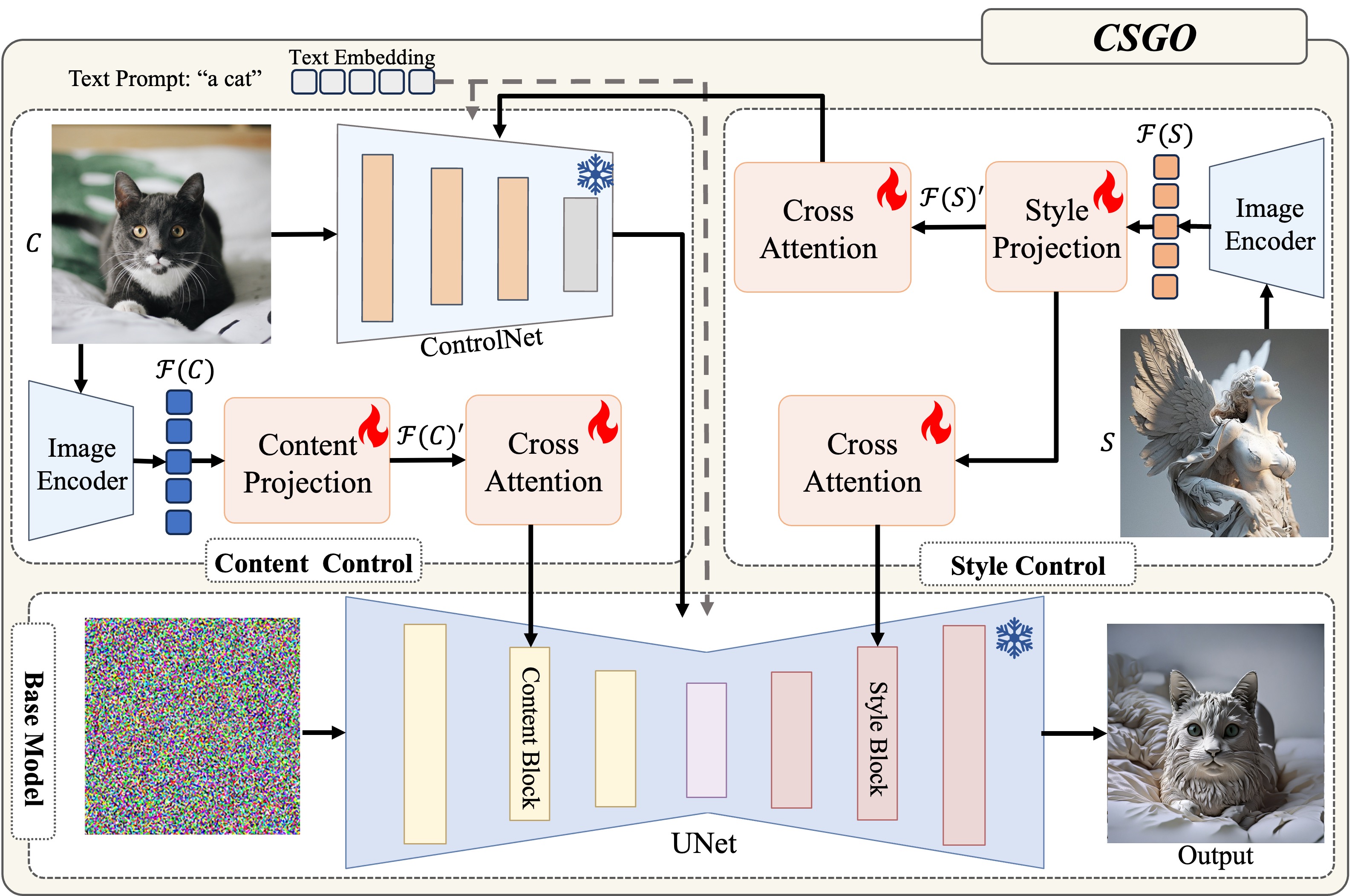
We differ from previous work in the following ways:(1) CSGO is a model based on end-to-end training. No fine-tuning is required for inference. (2) We do not train UNet and thus can preserve the generative power of the original text-to-image model (3) Our approach unifies image-driven style transfer, text-driven style synthesis, and text-editing-driven style synthesis.
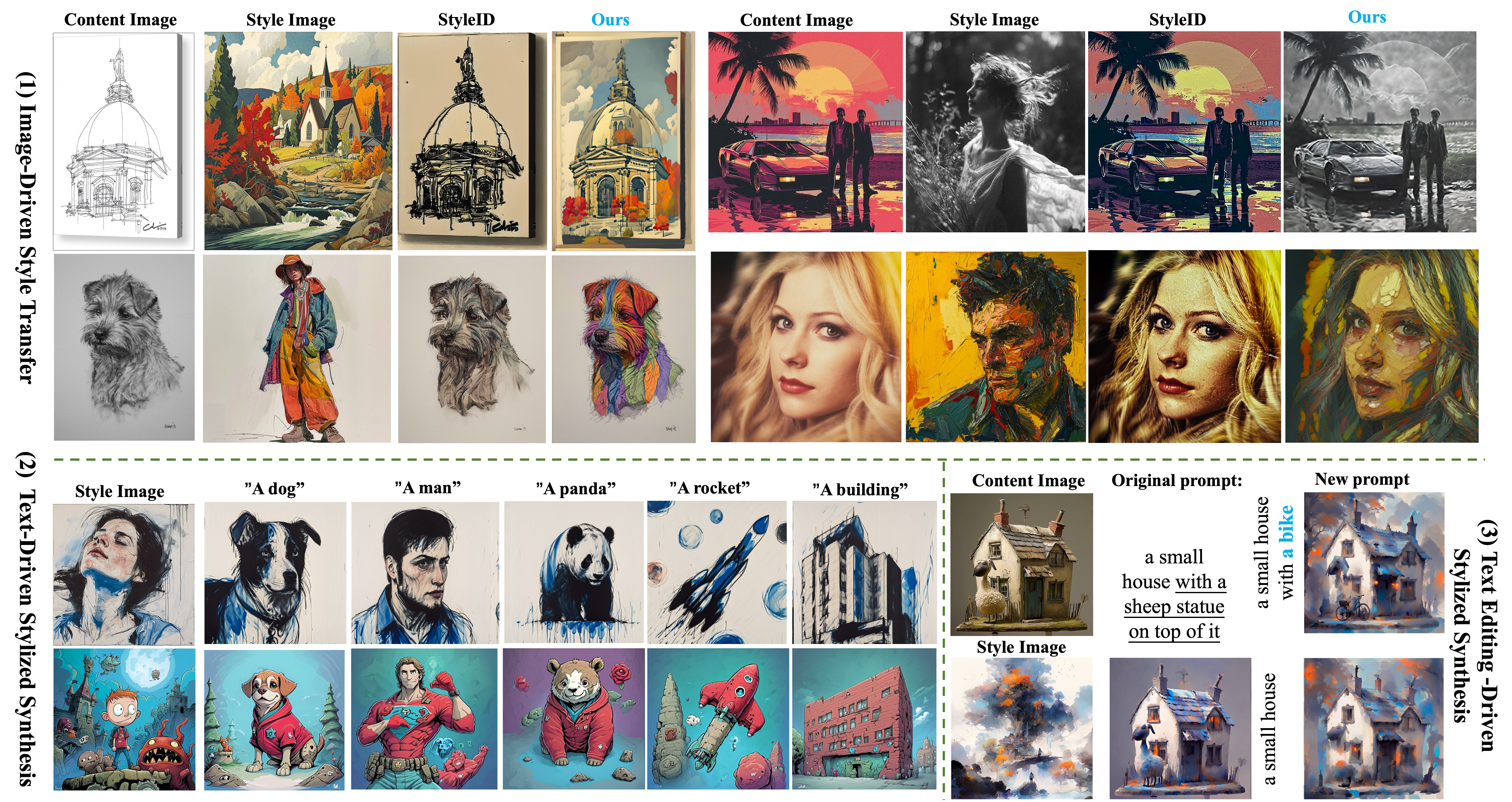
The visualisation image below shows the performance of CSGO. Quantitative and visual comparisons with recent methods can be found in the original paper.











@article{xing2024csgo,
title={CSGO: Content-Style Composition in Text-to-Image Generation},
author={Peng Xing and Haofan Wang and Yanpeng Sun and Qixun Wang and Xu Bai and Hao Ai and Renyuan Huang and Zechao Li},
year={2024},
journal = {arXiv 2408.16766},
}